OpenSees Cloud
OpenSees AMI
Better Than Ideal Conditions
08 Feb 2020 - Michael H. Scott
In simulating the nonlinear response of structural models, the Newton-Raphson algorithm converges quadratically as the iterations approach equilibrium at a time step. Quadratic convergence means the error at the current iteration is less than some constant times the square of the error at the previous iteration, e.g., the error is on the order of 10-3, 10-6, then 10-12 until convergence.
Quadratic convergence can be achieved only if the tangent stiffness matrix is algorithmically consistent with the residual equilibrium vector. This means the consistent tangent of every element and material in your finite element model must be derived and programmed correctly. For some material models, this is pretty straightforward. For others, getting the consistent tangent requires better than ideal conditions, like the rabbit-panther thingy in this Comcast commercial.

Frequently, conditions are less than ideal. Programming errors are common and the smallest error can lead to slow downs in convergence. Consider this example from my nonlinear structural analysis course in Eastchester.
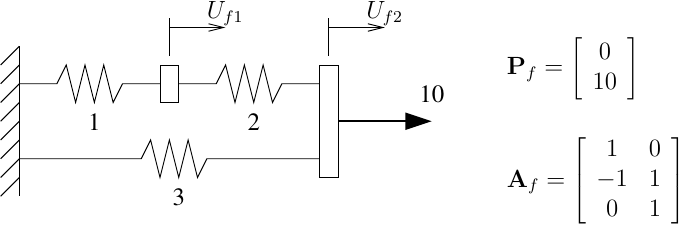
The basic spring forces are described by nonlinear functions
\[{\bf P}_b=\left[ \begin{array}{c} 10\arctan(u_{b1}^1) \\ 4\arctan(0.5u_{b1}^2) \\ 7\arctan(u_{b1}^3) \end{array} \right]\]where \(u_{b1}^j\) is the deformation of spring j. The residual equation for this model is \({\bf R}_f={\bf P}_f-{\bf A}_f^T{\bf P}_b\) and the tangent stiffness is \({\bf K}_T={\bf A}_f^T{\bf K}_b{\bf A}_f\) where the basic stiffness is
\[{\bf K}_b=\left[ \begin{array}{ccc} \frac{10}{(u_{b1}^1)^2+1} & 0 & 0 \\ 0 & \frac{2}{(0.5u_{b1}^2)^2+1} & 0 \\ 0 & 0 & \frac{7}{(u_{b1}^3)^2+1} \end{array} \right]\]Using the Newton-Raphson algorithm, convergence is quadratic for both the residual and the displacement increment. The convergence criterion is the norm of the residual less than 10-8. In OpenSees, the “residual” is referred to as the “unbalance”.
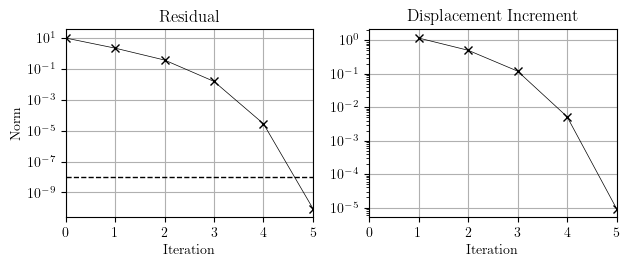
Note that the displacement increment lags behind the residual, so it is a good idea to base convergence on the norm of the displacement increment when using Newton-Raphson. This will ensure errors don’t accumulate over multiple time steps.
Now consider the case where the tangent stiffness of spring 2 is derived incorrectly by forgetting the chain rule of differentiation, i.e., the numerator of the spring 2 stiffness is 4 instead of 2.
\[{\bf K}_b=\left[ \begin{array}{ccc} \frac{10}{(u_{b1}^1)^2+1} & 0 & 0 \\ 0 & \frac{4}{(0.5u_{b1}^2)^2+1} & 0 \\ 0 & 0 & \frac{7}{(u_{b1}^3)^2+1} \end{array} \right]\]This is a small error, meant to represent a derivation or programming error in a more complicated model. Perhaps, the rabbit-panther thingy forgot to use a surgical grade razor. But with this error, convergence of Newton-Raphson is linear.
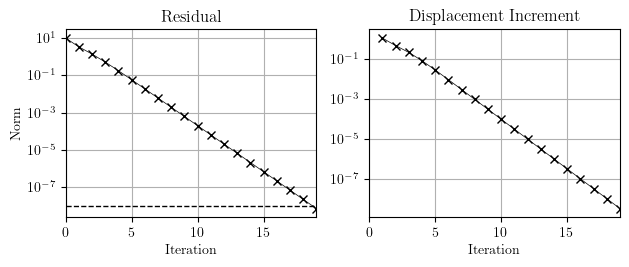
If you use Newton-Raphson and see this convergence behavior, there is an inconsistent tangent somewhere in your model. It’s also possible that errors in the tangent will send Newton-Raphson off in wild search directions from which the algorithm cannot recover. In either case, finding the error can be pretty difficult, but it’s best to swap linear elements for nonlinear elements one by one until you see which change leads to the return of quadratic convergence.
Beware that some models in OpenSees were knowingly implemented without consistent tangents. Perhaps the programmer implemented only an approximation of the consistent tangent. Or maybe the programmer decided to return the initial tangent for their implementation of Element::getTangentStiff() and let the global solution algorithm sort things out, like cleaning a rug by beating it with a tennis racket. It’s also possible that the high level analysis framework prevents quadratic convergence, e.g., the OpenSees implementation of modal damping has a damping tangent that is inconsistent with the damping force.
But if you know your model has inconsistent tangents, don’t be stubborn and use Newton-Raphson. Try using algorithms like Secant Newton, Krylov Newton, or BFGS that are able to overcome an error in the tangent. Because they don’t factorize the tangent stiffness matrix at every iteration, these alternatives can be more computationally efficient than Newton-Raphson for large models, even when those better than ideal conditions prevail.